Revisiting Data-driven Marketing
One of the key trends in the advertising industry is (digital) data-driven marketing. The whole thing starts with massive, passive data collection. No matter which website we visit or which app we use: We leave a digital footprint. These footprints are compiled for individual users and form so-called user profiles. A set of similar profiles is then aggregated to user segments, which aim at describing a homogeneous set of users with similar preferences and interests. In order to improve marketing activities, companies use these user segments to show them advertisements fitting the user’s interest. To be more concrete; users visiting car sites are more likely to see BWM or Daimler-Benz ads.
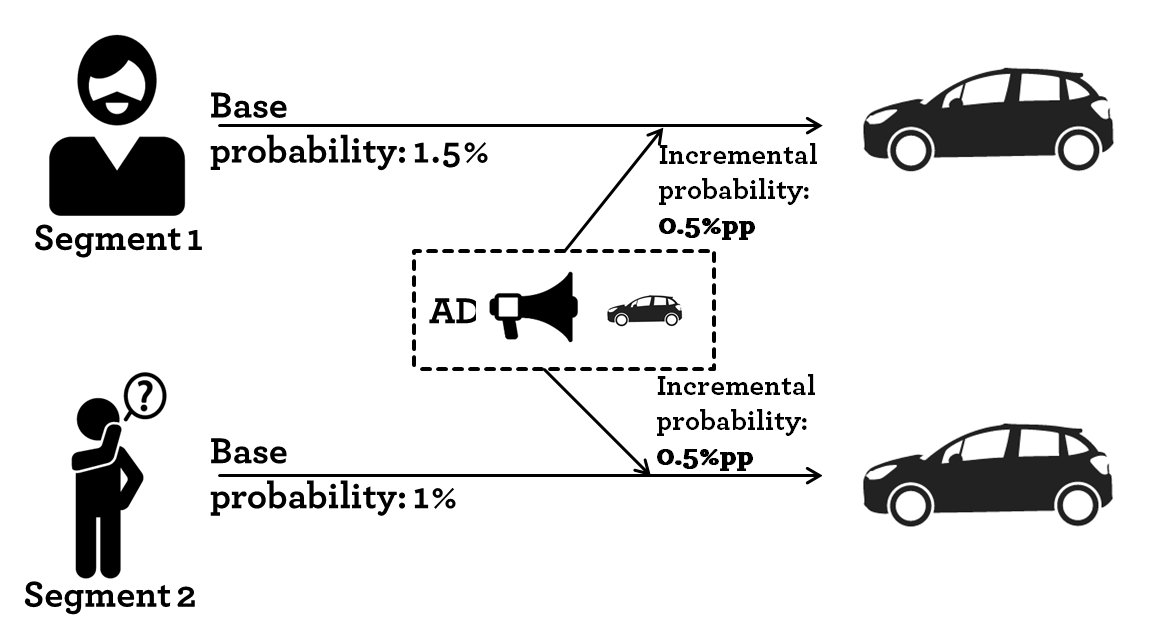
So far this sounds great. It is a win-win situation, advertisers reach an audience with an interest in their product and users see ads that mirror their interest. Well the key is; advertisers want to increase their advertising effectiveness. Let’s have a look at how advertising is measured. Let’s exemplify it by looking at the advertising for a car with two segments; a segment of car enthusiasts and a general population segment. Both segments receive the same ad.
The most common (and maybe intuitive) way to look at advertising effectiveness is by calculating the cost per order/conversion. The calculation is straight forward. The cost per order is: the ad spend by user segment divided by the number of orders generated in the user segment.
As segments are generated depending on the user interests, it is fair to assume that users have different base probabilities of buying the item (car) in question.
| User segment | #Users | Base probability | Ad uplift | Ad spend | #Orders | Cost per order |
|---|---|---|---|---|---|---|
| Car enthusiast | 100 | 1.5% | 0.50% | 10 000 € | 2 | 5 000 € |
| No Targeting | 100 | 1.0% | 0.50% | 10 000 € | 1.5 | 6 667 € |
Given the example, a naive marketeer concludes that targeting the car enthusiast segment is more effective as the cost per order is 1 667€ lower.
However that is only the easy way of calculating it. What you as a marketeer really want to measure is the incremental uplift. The uplift describes the increase in purchase probability when showing the user ads. The incremental uplift is only measurable by running (controlled) experiments, in which you measure the increase of sales in the segment exposed to ads to the “same” segment not exposed to ads. Such controlled experiments are rarely done on a segment basis.
In this example, both marketing activities have the same incremental uplift in purchase probability (0.5% p.p.). Hence, if you ignore that the marketeer have to buy targeting data on top of her media spend, the incremental uplift is the same for both groups as is the return for the ad investment.
This brings us to the key message; current systems (ad serving in particular) are designed in a way that they are basically unable to capture users base purchase probability. Hence, they are deeply flawed and purposefully biased towards benefiting targeted ad buying.