The Limits of AI: Why Automated Optimization (often) Fails in Smaller Markets
In my last post, I discussed that clicks are a bad metric to optimise against in advertising systems. However, optimising against metrics that are closer to conversion do have their limits. Basically, if feedback to AI systems (e.g. Ad optimisation systems) is too sparse, claims to automatically optimise / personalise ads do not hold up.
Short practical advice on ad optimization in smaller markets:
-
Know your feedback loop density — AI optimization systems require enough conversion events to learn. In small markets, you simply won’t have enough feedback to train reliable models.
-
Calculate required impressions upfront — Before launching complex tests (multiple creatives, multiple audiences), run the sample size math. If the numbers don’t add up to something achievable in your timeframe, simplify the test design.
-
Use higher-frequency proxies — When conversions are sparse, optimize for site visits, add-to-cart, or other mid-funnel events. These provide 10-100x more training signal.
-
Accept that US-designed systems don’t scale down — Platforms built for the US market (330M+ people) assume abundant data. The same algorithms don’t work when you have 1/50th the population.
-
Manual beats broken automation — If you need 34 million impressions for statistical significance but only have capacity for 2 million, human-designed targeting will beat AI that’s still “cold start.”
Long Version
AI-driven ad optimization and personalization systems are impressive. TikTok, Google, Meta; they can show you the right ad to the right person at the right time, learning and improving continuously. But there’s a dirty secret: these systems are built for the US/Chinese market.
When you try to use them in smaller markets like Germany (80 million people) or Sweden (10 million), the math breaks down. The feedback loop that enables AI learning becomes too sparse for the algorithms to work.
This isn’t about AI quality — it’s about sample size. And the implications are brutal for anyone running sophisticated ad campaigns outside the world’s largest markets.
The fundamental constraint: events per model
AI optimization systems learn from feedback. Every conversion (or proxy event) is a training example. The more examples, the better the model. But there’s a threshold below which learning simply doesn’t happen.
In the US, with 330 million people and billions of ad impressions daily, you accumulate training data rapidly. In Sweden, with 10 million people, you might get 1/30th the volume — but the AI system doesn’t need 1/30th the data. It needs roughly the same amount of data to converge.
The result: AI optimization never converges. It’s perpetually in “cold start” mode, making decisions based on noise rather than signal.
Sample size reality check
Let me work through a concrete example. Say you want to run an A/B test comparing ad creatives:
- CTR = 0.5% (typical for display ads)
- Click-to-Conversion Rate = 2% (people who click and convert)
- This gives us an impression to Conversion Rate = 0.01%
- We want to detect which creative is 30% better than the others
How many impressions do we need?
3 creatives
Just 3 variations of the same ad:
# Sample size calculation for detecting 30% lift in LPEV
# Base rate: 0.01% (CTR 0.5% x Conversion 2%)
base_rate <- 0.0001 # 0.01%
lift_to_detect <- 0.30 # 30% improvement
alpha <- 0.05
power <- 0.80
# For 3 arms (3 comparisons), need Bonferroni correction
# Z for 95% confidence with 3 comparisons
z_alpha <- qnorm(1 - (0.05 / 6))
z_beta <- qnorm(power)
delta <- base_rate * lift_to_detect
# Sample size per arm
n_per_arm <- ((z_alpha + z_beta)^2 * 2 * base_rate * (1 - base_rate)) / (delta^2)
n_per_armThis gives us approximately 2.3 million impressions per creative.
Total for 3 creatives: ~7 million impressions
5 creatives
Testing 5 different ads means 10 pairwise comparisons. This pushes the sample size up:
| Scenario | Impressions per arm | Total impressions |
|---|---|---|
| 3 creatives | ~2.3M | ~7M |
| 5 creatives | ~3.0M | ~15M |
| 9 arms (3 audiences × 3 creatives) | ~3.8M | ~34M |
Personalisation of Ads: The 9-arm problem
Now imagine testing 3 different audience segments with 3 creatives each — 9 total variations. You need 34 million impressions for statistical significance.
R simulation: Sample size by arm count
Let me visualize how sample size grows with complexity:
library(ggplot2)
library(dplyr)
library(scales)
set.seed(42)
# Parameters
base_rate <- 0.0001 # 0.01% LPEV
lift <- 0.30 # 30% improvement to detect
# Sample sizes for different numbers of arms
arms <- c(2, 3, 5, 9, 15)
comparisons <- sapply(arms, function(n) n choose 2) # Pairwise comparisons
alpha_adjusted <- 0.05 / comparisons
# Z-scores for each scenario
z_alpha <- qnorm(1 - alpha_adjusted / 2)
z_beta <- qnorm(0.80)
delta <- base_rate * lift
sample_per_arm <- ((z_alpha + z_beta)^2 * 2 * base_rate * (1 - base_rate)) / (delta^2)
total_impressions <- sample_per_arm * arms
df_sample <- data.frame(
arms = factor(arms),
per_arm = round(sample_per_arm / 1e6, 1),
total = round(total_impressions / 1e6, 1)
)
ggplot(df_sample, aes(x = arms, y = total, fill = arms)) +
geom_col(alpha = 0.7) +
geom_text(aes(label = paste0(total, "M")),
vjust = -0.5, size = 4, fontface = "bold") +
scale_y_continuous("Total impressions (millions)",
labels = comma_format(),
limits = c(0, 45)) +
scale_fill_viridis_d(option = "plasma") +
labs(title = "Sample Size Explodes with Test Complexity",
subtitle = "Detecting 30% lift at 0.01% conversion rate",
caption = "US-scale campaigns can hit these numbers; smaller markets never will") +
theme_minimal(base_size = 12) +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1))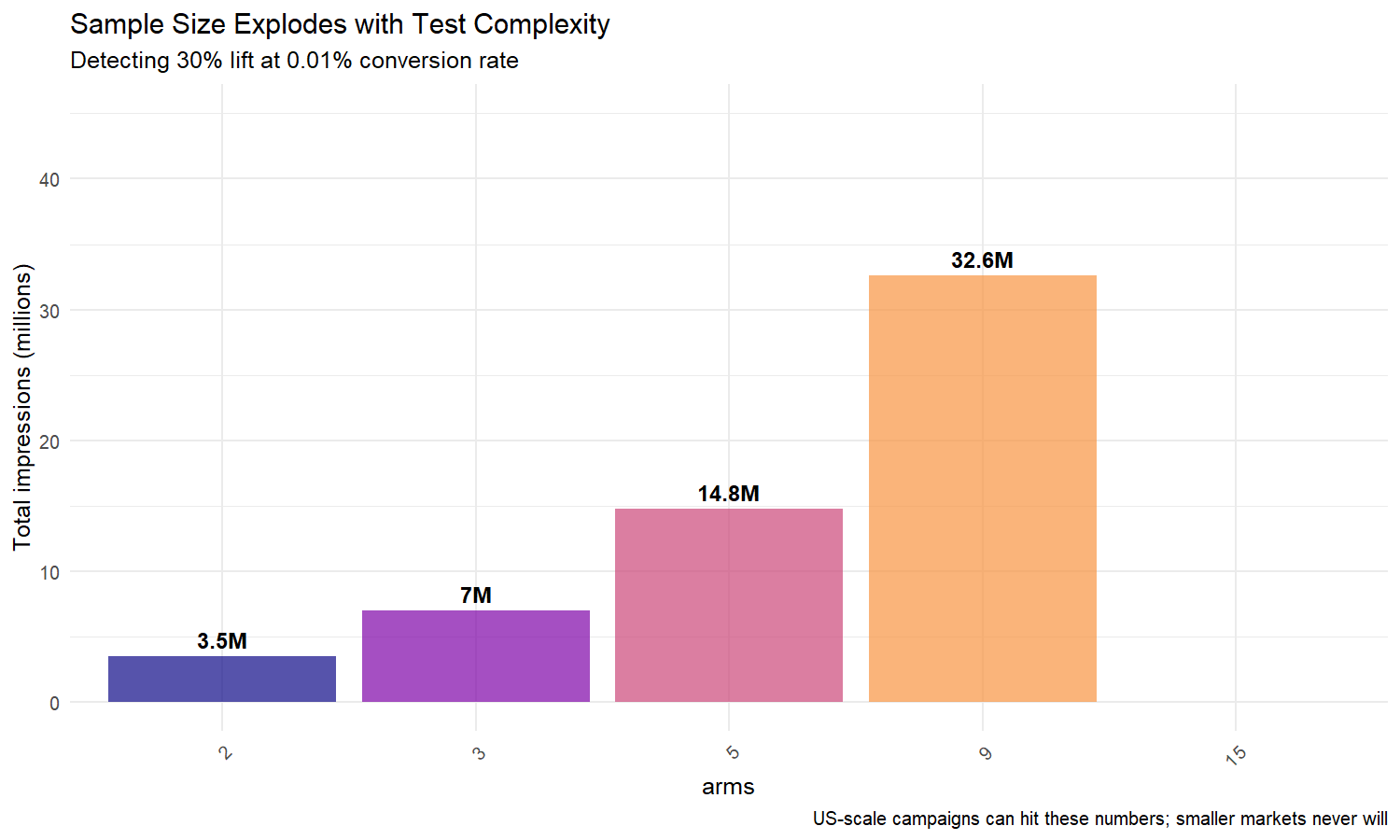
The key insight: sample size grows super-linearly with the number of arms. 9 arms require nearly 5x the impressions of 2 arms.
The market size problem
Now let’s compare market sizes:
| Market | Population | Daily ad impressions | Time to 34M impressions |
|---|---|---|---|
| US | 330M | ~5M | ~7 weeks |
| Germany | 80M | ~0.5M | ~68 weeks |
| Sweden | 10M | ~0.1M | ~85 weeks |
In the US, a 9-arm test converges in a couple of weeks. In Sweden, the same test takes almost two years; by which time the market has changed, the creatives are stale, and the test results are meaningless.
The per capita problem
It’s not just about total market size. It’s about per capita conversion events.
AI systems don’t learn from total population — they learn from events per user. If your population is 1/30th the size, and your spend scales proportionally, you get 1/30th the events. But the AI system needs the same number of events to reach the same level of sophistication.
What actually happens in practice
When you deploy US-designed AI optimization in smaller markets, here’s what occurs:
-
The system never leaves cold start: It’s perpetually uncertain, changing targets randomly based on noise.
-
Oversimplification occurs: To get any signal, the system lumps users into broad segments. “Personalization” becomes barely better than random.
-
Wrong optimizations: When the system does make a decision (e.g., Creative A beats Creative B), it’s often statistically invalid. The “winner” won by random chance, not actual performance.
-
Feedback loop damage: Bad early decisions reinforce themselves. The system optimizes toward the wrong target, creating a local optimum that’s hard to escape.
Solutions for smaller markets
If you’re running sophisticated ad campaigns outside the US, what can you do?
1. Simplify test design
Don’t run 9-arm tests. Run 2-arm tests (A/B), or even single-variant campaigns with clear hypotheses. The math becomes tractable:
- 2 arms: ~2 million impressions
- 3 arms: ~7 million impressions
- 9 arms: ~34 million impressions
2. Use higher-frequency proxies
Instead of optimizing for purchases (0.01% rate), optimize for:
- Site visits (1-2% rate) — 100-200x more events
- Add-to-cart (0.5-1% rate) — 50-100x more events
- Page engagement metrics (0.5-2% rate) — varies by page
This is exactly what Dalessandro et al.’s paper recommends (see last post). A proxy with 1% rate needs ~100x fewer impressions than one with 0.01% rate.
3. Pool across markets
If you operate in multiple smaller markets, consider:
- Training on pooled data, applying locally (with geographic controls)
- Running pan-European tests when individual country tests aren’t feasible
- Using global models with regional fine-tuning
4. Accept manual beats broken automation
Sometimes the best “AI” is a human who understands:
- Your specific market dynamics
- Seasonal patterns unique to your region
- Creative and messaging that resonates locally
An experienced media planner making decisions based on domain knowledge will beat an AI system that’s still in cold start after two years of “learning.”
The broader lesson
This isn’t just about advertising. It’s about a fundamental limitation of AI: systems require sufficient feedback density to work.
We’re seeing US-designed AI being deployed globally — in HR, healthcare, finance, logistics — without consideration for whether there’s enough local data to make the algorithms work. The results are predictably bad.
In advertising, the symptom is endless “learning” that never converges. In other domains, it looks like biased recommendations, poor predictions, or system instability.
Before deploying AI optimization in ad systems, ask:
- How many feedback events do we get per time period?
- How many does the algorithm actually need to converge?
- Will we ever reach that number in this market?
If the answer is no, simplify. You’ll be worse off trusting feedback-based AI optimnisation, than a using simpler system that matches your constraints.
Takeaways
AI optimization systems are powerful, but they’re not magic. They need data, lots of it, and smaller markets simply don’t provide it.
The US-centric design of most ad platforms means sophisticated features break down when you scale down. In markets like Germany or Sweden, the right approach is often:
- Simpler test designs
- Higher-frequency proxies
- More human oversight
- Acceptance that “full personalization” isn’t mathematically feasible
Sometimes the most sophisticated solution is to recognize the limits of sophistication.