IMDB Genre Classification using Deep Learning
The Internet Movie Database (Imdb) is a great source to get information about movies. Keras provides access to some part of the cleaned dataset (e.g. for sentiment classification). While sentiment classification is an interesting topic, I wanted to see if it is possible to identify a movie’s genre from its description. The image illustrates the task;
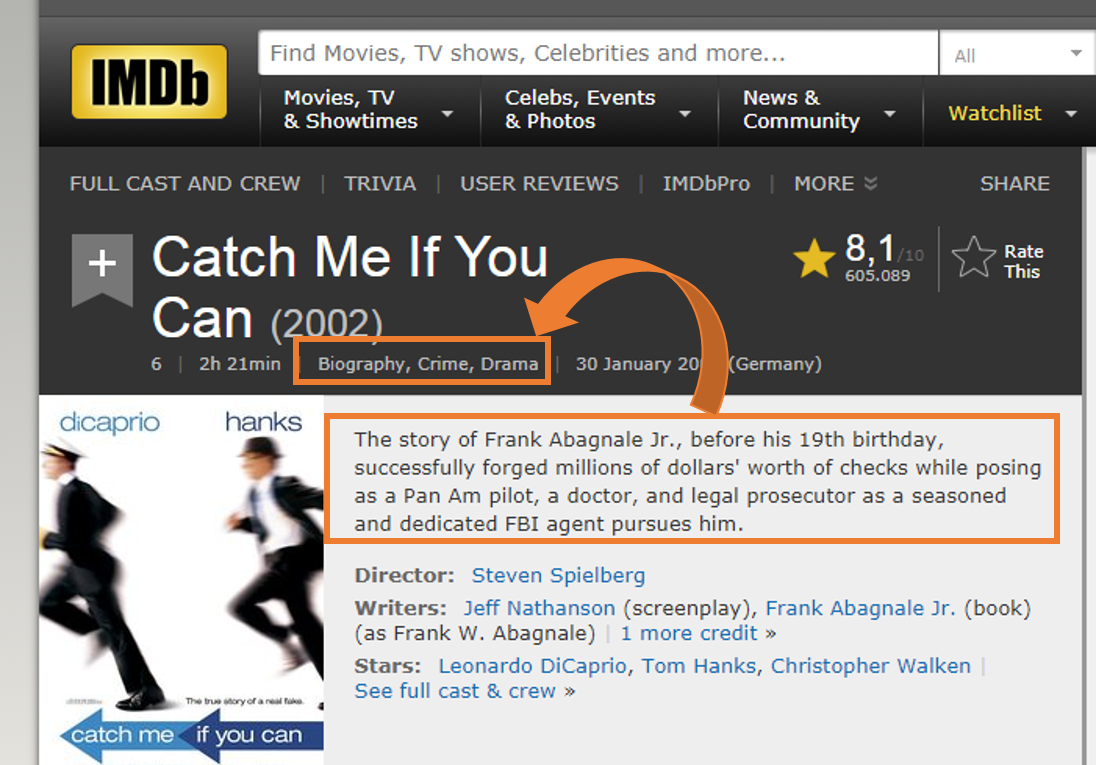
To see if that is possible I downloaded the raw data from an FU-Berlin ftp- server. Most movies have multiple genres assigned (e.g. Action and Sci-fi.). I chose to randomly pick one genre in case of multiple assignments.
So the task at hand is to use a lengthy description to infer a (noisy) label. Hence, the task is similar to the Reuters news categorization task. I used the code as a guideline for the model. However, looking at the code, it becomes clear that data preprocessing part is skipped. In order to make it easy for a practitioner to create their own applications, I will try to detail the necessary preprocessing. The texts are represented as a vector of integers (indexes). So basically one builds a dictionary in which each index refers to a particular word.
require(caret)
require(keras)
max_words <- 1500
### create a balanced dataset with equal numbers of observations for each class
down_train <- caret::downSample(x = mm, y = mm$GenreFact)
### preprocessing ---
tokenizer = keras::text_tokenizer(num_words = max_words)
keras::fit_text_tokenizer(tokenizer, mm$descr)
sequences = tokenizer$texts_to_sequences(mm$descr)
## split in training and test set.
train <- sample(1:length(sequences),size = 0.95*length(sequences), replace=F)
x_test <- sequences[-train]
x_train <- sequences[train]
### labels!
y_train <- mm[train,]$GenreFact
y_test <- mm[-train,]$GenreFact
########## how many classes do we have?
num_classes <- length(unique(y_train)) +1
cat(num_classes, '\n')
#'Vectorizing sequence data to a matrix which can be used an input matrix
x_train <- sequences_to_matrix(tokenizer, x_train, mode = 'binary')
x_test <- sequences_to_matrix(tokenizer, x_test, mode = 'binary')
cat('x_train shape:', dim(x_train), '\n')
cat('x_test shape:', dim(x_test), '\n')
#'Convert class vector to binary class matrix',
# '(for use with categorical_crossentropy)\n')
y_train <- to_categorical(y_train, num_classes)
y_test <- to_categorical(y_test, num_classes)In order to get a trainable data, we first balance the dataset such that all classes have the same frequency. Then we preprocess the raw text descriptions in such an index based representation. As always, we split the dataset in test and training data (90%). Finally, we transform the index based representation into a matrix representation and hot-one-encode the classes.
After setting up the data, we can define the model. I tried different combinations (depth, dropouts, regularizers and input units) and the following layout seems to work the best:
batch_size <- 64
epochs <- 200
model <- keras_model_sequential()
model %>%
layer_dense(units = 512, input_shape = c(max_words), activation="relu") %>%
layer_dropout(rate = 0.6) %>%
layer_dense(units=64, activation = 'relu', regularizer_l1(l=0.15)) %>%
layer_dropout(rate = 0.8) %>%
layer_dense(units=num_classes, activation = 'softmax')
summary(model)
model %>% compile(
loss = 'categorical_crossentropy',
optimizer = 'adam',
metrics = c('accuracy')
)
hist <- model %>% fit(
x_train, y_train,
batch_size = batch_size,
epochs = 200,
verbose = 1,
validation_split = 0.1
)
## using the holdout dataset!
score <- model %>% evaluate(
x_test, y_test,
batch_size = batch_size,
verbose = 1
)
cat('Test score:', score[[1]], '\n')
cat('Test accuracy', score[[2]], '\n')Finally, we plot the training progress and conclude that it is possible to train a classifier without too much effort.
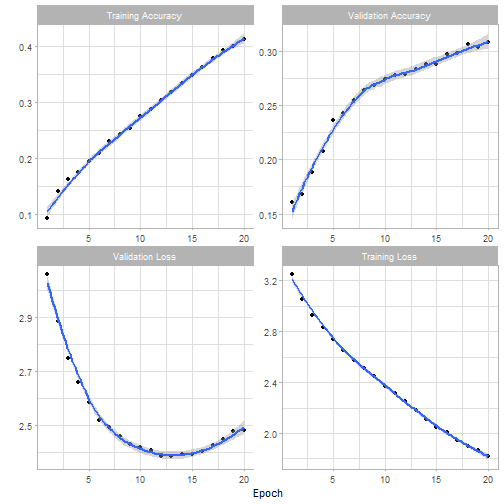
I hope the short tutorial illustrated how to preprocess text in order to build a text-based deep-learning learning classifier. I am pretty sure that are better parameters to tune the model. If you want to implement such a model in production environment, I would recommend playing with the text-preprocessing parameters. The text-tokenizer and the text_to_sequence functions hold a lot of untapped value.
Good luck!