Revisiting Data-driven Marketing, part II
In the last post, I discussed how the current digital measurement approach is biased towards targeted ad buying. The key reason is that ad effectiveness is calculated on a cost per order/conversion basis. As particular user segments -which are addressed with digital targeting- have a high base purchase probability, the segment looks more responsive. Due to insufficient experimentation and proper measurement, the budget optimization tries to reach users who are likely to order/”convert” anyway. Hence, it ignores incremental effects and instead focuses on overall purchase probabilities, mixing base purchase probability and ad-driven incremental effects.
Let’s go back a step and have a look at two scenarios. Scenario A is taken from the previous post. There are two user segments; a segment of car enthusiasts and a general population segment. Both segments receive the same ad. The car enthusiasts (Segment 1) have a higher base probability of purchasing a car. As discussed that leads to a lower cost per order for that group and sub-sequentially to a misguided budget shift.
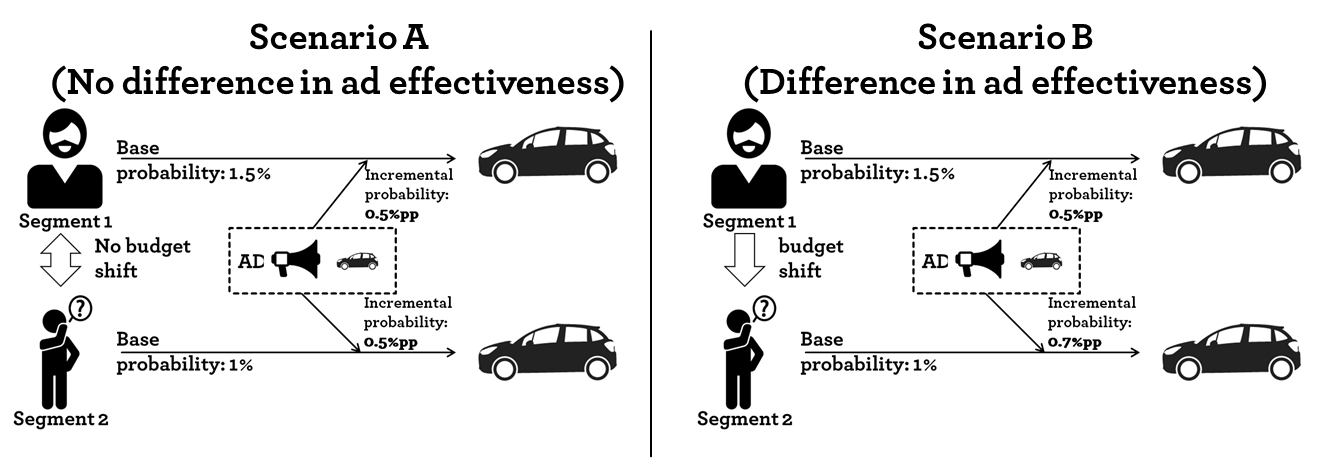
Let’s add the second Scenario B. In this case the incremental effect of showing an ad is higher in the general population segment (Segment 2) compared so Segment 1. It might be that the ad communicates a new feature (Matrix LED lights, head-up-display,…) that Segment 1 was not aware of before. In that scenario a budget shift would increase the overall sales. However, that budget shift would only be realized if the incremental effect would have been measured. The cost per order is still lower for Segment 1.
To sum up, current systems try hard to minimize the cost per conversion. This leads to showing ads to users who are likely to convert anyway, if possible. From a theoretical point of view, (e.g. assuming that targeting works perfectly) that leads to an overall decreasing ad effectiveness.