On Panel Sizes
In the face of upcoming elections in the US and in Germany, polling is big news. One thing that strikes me as enormously missing in the debate is how inaccurate a single poll is. Moreover, one never reads about the uncertainty around a single poll. What is the range of expected outcomes or a least a confidence interval? I am by no means an expert on polling, but I thought some simulations would help me interpreting the headline figures more accurately. In Germany most of the time, polling institutes ask around 1000 individuals to get a representative view. Using exemplary vote shares of (40, 30, 15, 10 , 5) %, I simulated 100 polls and potential outcomes.
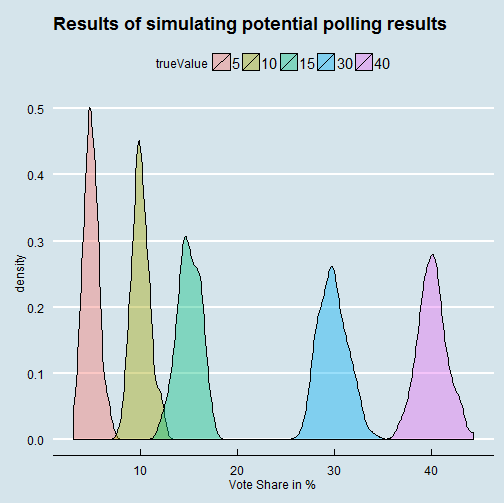
The chart illustrates what polling results we would expect given the “true value” of a single party. Let’s assume a party (purple) with a “true” vote share of 40%, given the population size (70 Mio.) and the sample size (1000), we can expect polling results somewhere between 36% and 44%.
Another way to represent the uncertainty is by providing confidence intervals.
confidence.interval(95, 0.4, 1000, 70000000)## [1] 3.04For the case above, we see that in 1 out of 20 cases (95%-interval), the expected polling result is between 40% +/- 3.04. Also for parties with small vote share we see a smaller absolute confidence interval.
confidence.interval(95, 0.04, 1000, 70000000)## [1] 1.21For example, for a party with 4% true vote share the expected result is between 2.8% and 5.2%. However, the relative polling error is more severe for smaller parties. Both is consistent with the simulated chart above.
Panel-based Media Measurement
Panels are not only used to gather data on voter behavior but also to understand media audiences. For example, the GFK runs a 5000-household panel to measure TV viewership second by second for ~65 channels. While measurement error is annoying in the political discussion, it is more serious in the TV market for two reasons.
First, economically speaking the panel acts as currency. Advertisers buy audience on a cost per mille basis. Hence, if the measurement is off by 10% so is the payment for showing your ad on TV.
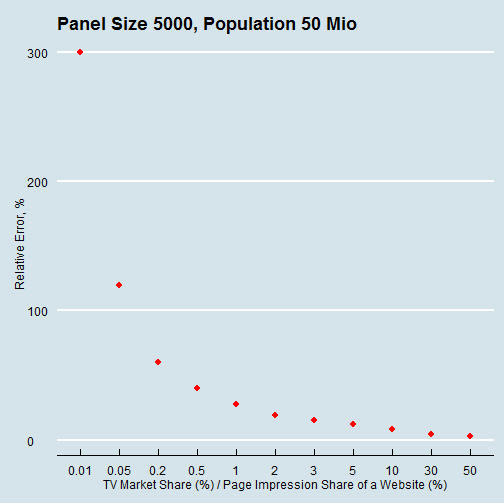
To exemplify this, for the show on the 22nd of January 2016; ARD Sportschau live at 08:15PM, the GFK panel reports a viewership of 4.19 Mio with a market share of 13%. Given the panel size, we get a confidence interval of 1 percentage point.
confidence.interval(95, 0.13, 5000, 50000000)## [1] 0.93Hence, the actual viewership might also be 3.87 Mio.
Second, the relative potential error increases when measuring or reporting smaller channels. If the market share of a channel decreases the relative error increases. The following chart shows the non-linear relationship. With most of TV channels having less than 1% market share, it looks like audience reports cannot be reliable, statistically speaking. However, errors cancel out, if advertisers book more than a couple of spots and as long as there is no systematic bias in the panel.
With increasing online video usage, advertisers are shifting TV budgets towards online video platforms. Pretty similar to GFK for TV, Nielsen maintains an online panel to measure usage and demographic distribution. However, there is one big catch; Online usage is much more heterogeneous than broadcast TV usage. With many more options (channels) usage is spread among a very high number of websites. With small “market shares”, one needs a much bigger panel to calculate reliable usage metrics.
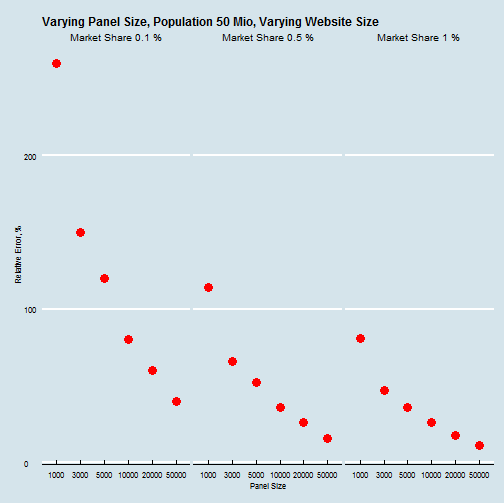
The chart above illustrates this. Plenty of websites have less than 0.1% impression market share. To measure their audience, one would need at least a panel of 50 000 users (who allow to measure their usage across all their devices). Nielsen apparently has a panel of ~20 000 users.
There is no (open) discussion about the accuracy of panel-based audience measurement. Advised audience reach figures appear to be exact in almost all reports. Same as in the public polling figures, uncertainty is not a metric that is properly reported and discussed. It seem that decision makers and consumers don’t want to be reminded on how fragile parts of the data are.
Some of the code to run the analysis: