The Instant Rise of Machine Intelligence?
Currently the news are filled with articles about the rise of machine intelligence, artificial intelligence and deep learning. For the average reader it seems that there was this single technical breakthrough that made AI possible. While I strongly believe in the fascinating opportunities around deep learning for image recognition, natural language processing and even end-to-end “intelligent” systems (e.g. chat bots), I wanted to get a better feeling of the recent technological progress.
First I read about tensorflow (for R) and watched a number of great talks about it. Do not miss Nuts and Bolts of Applying Deep Learning (Andrew Ng) and Tensorflow and deep learning - without at PhD by Martin Görner. Second I started to look at publications and error improvements on public datasets. There is surprisingly little information about the improvement rate of machine learning on public datasets. I found one great resource I would like to analyse in the following post. All datasets (“MINST”,”CIFAR-10”, “CIFAR-100”, “STL-10”, “SVHN”) are image classification tasks and results are published in academic (peer-reviewed) outlets. In order to better aggregate the results, I report the trimmed (10 percent) mean error rate per year per dataset.
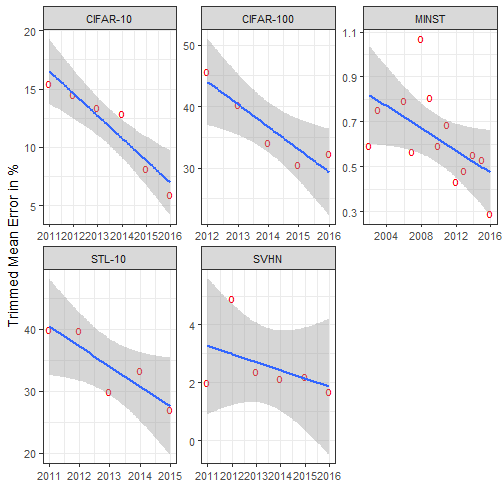
We see that the mean reported error drops in all datasets per year. Each panel has it’s own x,y-scales, however inspected closely, we see that there is no apparent drop in the error rate in one particular year. Rather, it seems that the improvement rate per dataset is a linear function of the time. To get a better look at the best performer, let’s do the same plot with just the lowest reported error rates per year.
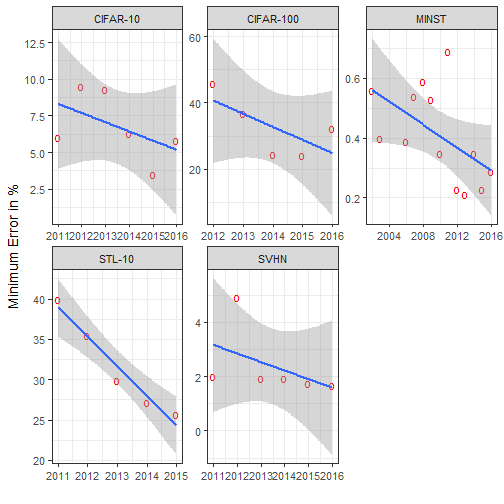
Again, there is not a single year that appears to mark the rise of machines but it looks like a continuous process. If it is a continuous process, let’s quickly summarise the learning rate per dataset.
| Dataset | Improvement | Years | PP. Improvement per Year |
|---|---|---|---|
| CIFAR-10 | 3% | 6 | 0.4% |
| CIFAR-100 | 29% | 5 | 5.9% |
| MINST | 63% | 13 | 4.8% |
| STL-10 | 36% | 5 | 7.1% |
| SVHN | 16% | 6 | 2.6% |
The improvement column lists the percent improvement from the first year best publication to the current best publication. The dataset have been around for various timeframes (indicated in column 2). Finally we get the percentage point increase per year. While the improvement varies, across the board it seem that 5% improvement is reasonable.
So if there is not a single year that marks instant spike in improvement, what is the hype about? I assume that with the steady process in the recent years AI seems to approach or even surpass human-level performance on some tasks. Basically the news is not a technology breakthrough but rather a passing of an important threshold.
18.01.2017, Edit: Deep-diving in the topic for 2 weeks, it slighly changed my perspective on the current process. Jermey Howard shows how to be better than most peer-reviewed models with a CNN in less than 10 minutes. Check out his amazing youtube video (Model development is presented close to the end). Hence, my changed take-away is that it is the massively enhanced availablity of deep learning methods that drives the current hype.
01.02.2017, 2nd Edit: I found a more detailed analysis of performance improvements through deep learning. The author concludes that it is not clear if the discontinuous advancements in NLP and image recognition are due to the algorithm or increases in processing power (usage of GPUs). Moreover looking at other domains the author does not find the performance jumps.
In case you want to have a look at the data yourself: