Deep Learning for Brand Logo Detection
A year ago, I used Google’s Vision API to detect brand logos in images. Since then the DIY deep learning possibilities in R have vastly improved. With the release of Keras for R, one of the key deep learning frameworks is now available at your R fingertips.
Following up last year’s post, I thought it would be a good exercise to train a “simple” model on brand logos. For that, I downloaded the Flickr27-dataset, containing 270 images of 27 different brands. Just to give you an impression, here are some of them:

There are at least two points to remember; the dataset is really small -especially to train a deep neural network, and some brands are hard to recognize, even for the human eye. In order to use the data for the Keras infrastructure, I created a small script to pre-process the image files. (Please find the full code at the end of the post). Also, I removed the images with no brand logo, the “none”-category.
In order to use Keras you have to follow their short guide:
#devtools::install_github("rstudio/keras")
#library(keras)
#install_tensorflow()With Keras installed, I defined a sequential model, following various sources. (I have to admit; I used a very rough trial and error approach. I would love to detail the approach but I cannot recall how many and which combinations I tried.)
model <- keras_model_sequential()
model %>% ## we use a smaller filter!
layer_conv_2d(filter = 16, kernel_size = c(3,3), input_shape = c(img_width, img_height, 3)) %>%
layer_activation("relu") %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_conv_2d(filter = 32, kernel_size = c(3,3)) %>%
layer_activation("relu") %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_conv_2d(filter = 64, kernel_size = c(3,3)) %>%
layer_activation("relu") %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_flatten() %>%
layer_dense(64) %>%
layer_activation("relu") %>%
layer_dropout(0.5) %>%
layer_dense(27) %>% ## we have 27 brand logo classes!
layer_activation("softmax")There are two parts I can detail; a) I used a 16 pixel filter, b) as the dataset contains 27 logos or (classes), the last layer is set to 27.
When compiling the model, it is important to set the loss to “categorical_crossentropy” as I try a multi-class classification.
hist <- model %>% compile(
loss = "categorical_crossentropy",
optimizer = optimizer_rmsprop(lr = 0.0001, decay = 1e-6),
metrics = "accuracy"
)Another parameter that I changed somehow randomly is the learning-rate (lr) parameter. In a follow-up post, I might show the effect of different learning rates on the model.
So how good can we get with this trial and error approach? The model is quickly well trained on the training examples, with an accuracy of almost 100% after 150 training steps (Epochs).
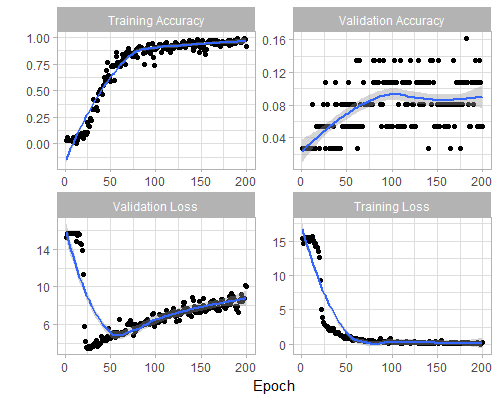
However, looking at the validation the accuracy, we see a lot of room for improvement with an accuracy of ~15%. Taking in consideration that the base probability of is 1/27 = 3.7%, the 15% are at least a decent uplift compared to random guessing.
To sum up; keras for R makes the deep learning infrastructure really easy to handle. Setting up a model is quick and the examples provide some very good starting points. However, training and tuning a model to new data is far from straight-forward. Even if a model fits the underlying problem structure, the parameter-space is not easy to grasp and the guidelines on how to set them are not (yet) well documented. All in all; there is no free lunch in deep learning ;)
In the following weeks, I plan to elaborate on the existing model, detailing the parameter space, use a pre-trained image model and increase the number of training images.