Image Recognition and Object Detection with R/Shiny and Google Vision
Image recognition and object detection has been around for some years. However, usage and adoption was limited due to quality and ease of development. With the release of Microsoft’s Project Oxford, and Google’s Vision API, the accessibility and applicability has massively improved. Both APIs use REST API access and provide an excellent opportunity for the average developer to augment their apps with fancy -state of the art- machine learning features. In a previous post I discussed Microsoft’s offering. In this post I give the Google’s Vision API a shot, especially the object detection functionality.
To give you an example how this looks like:
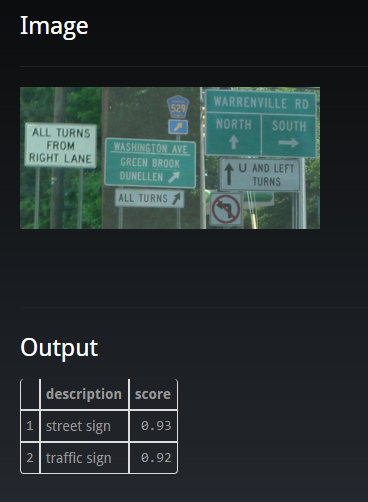
The API detect that there is a street sign and/or a traffic sign in the picture with a confidence score of 93 (92) out of 100.
Let’s take a look at a more complex (and ridiculous) example; an elephant sitting on a car.

The API gets the elephant/wildlife right with high confidence, it misses the car entirely though.
To come back to my previous post, let’s have a look at Arnold Schwarzenegger and his wife:
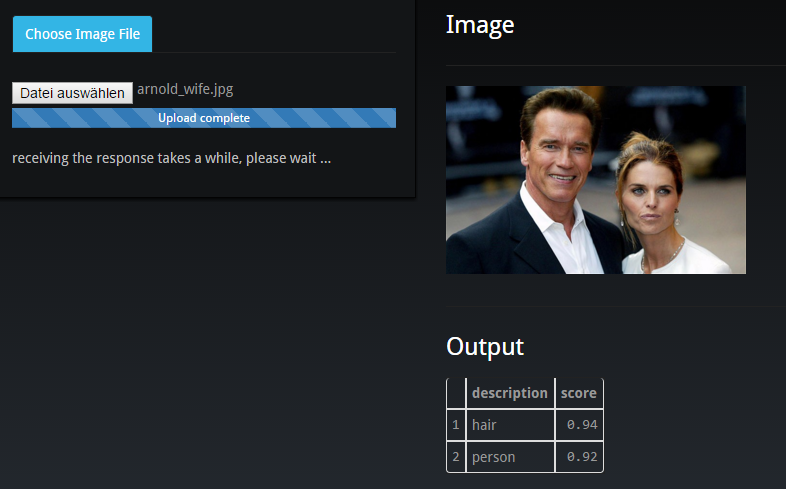
In case you want to try it yourself, head over to my minimalistic R/shiny implementation; upload an image with (objects) and wait a bit.
To sum up; giving the complexity of object detection in images, I find it pretty amazing (and scary!) how easy it is. Given the potential I various business contexts, I expect a number of services using such APIs.